

达到国际先进水平!同方知网数科KBase数据库管理系统通过科技成果评价
近日,由国家工业信息安全发展研究中心组织的“KBase数据库”项目科技成果评价会在北京召开。来自清华大学、北京大学、中国科学院软件研究所、北京理工大学、南京大学等顶尖机构的权威专家组成评价委员会,经过严格评审,一致认定:“该成果核心技术具有自主知识产权,整体技术水平达到国内领先,在专业知识管理与检索领域达到国际先进,具有广阔的应用前景和显著的经济社会效益。”

该成果展现了完整的自主技术架构体系,其底层核心引擎完全基于C/C++语言自主开发,构建了包括逻辑解析层、智能索引层、分布式存储计算层及统一服务接入层的整体架构。该架构支持多模数据的统一存储与管理,并通过自主研发的KSQL查询语言,为用户提供跨模型的统一数据访问接口。在安全性方面,其分布式集群架构支持多副本机制,确保了数据的可靠性与服务连续性,为关键行业领域提供了安全稳定的数据底座支撑。
此次通过科技成果评价,标志着KBase数据库的技术创新与应用成熟度获国家级认可。在AI时代,数据智能是企业核心竞争力的关键。同方知网数科将继续秉持自主创新理念精神,持续优化产品性能,深化在人工智能、大数据分析等场景的应用,为各行业提供更强大、更安全、更可靠的国产基础软件支撑,助力数字经济高质量发展。
一、KBase数据库简介
KBase是知网自主研发的多模型数据库管理系统,全称为KBase多模数据库管理系统。集成了智能信息处理与中文文本挖掘技术,通过统一接口实现跨模型数据访问与操作,具备相似检索、文本指纹等特色功能。全面适配国产化环境,内核自主可控,支持分布式集群、读写分离与多副本机制,具备高精度、高性能、高扩展、高安全、AI集成特性。
二十余年来KBase作为知网学术知识资源总库检索平台的核心数据引擎,支持近3亿数据管理,日千万级查询、上千台分布式集群管理以及亿级数据实时运行监控,数百个知识服务产品的生产、传播、安装、应用也均依托于KBase密不可分,赋能数据应用场景完全契合科研、教育、技术革新、管理创新等知识服务与知识管理需求。
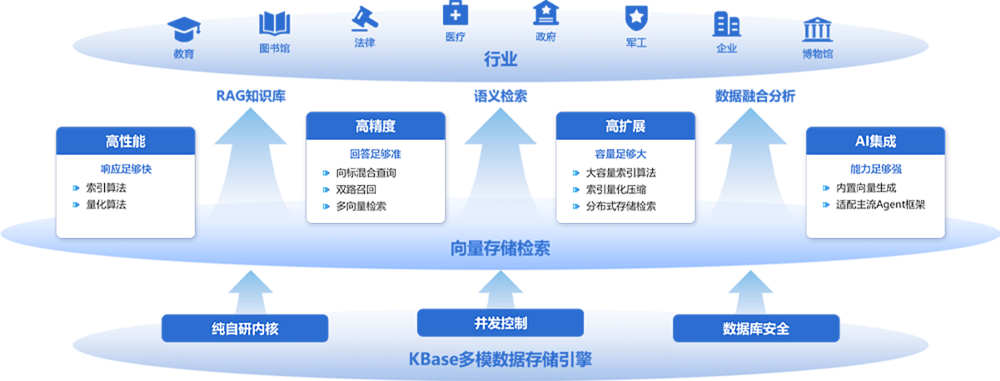
响应国家信创国产化政策与AI融合趋势,KBase数据库所包含的向量数据库引擎专为AI场景设计,支持跨模态相似性搜索与复杂向量计算,深度融合大模型的自然语言处理与语义理解能力,可赋能各垂直领域的专用大模型,显著增强其检索效果,为用户提供从数据处理、管理与智能应用的全链路解决方案。
二、KBase数据库的四大核心创新点
(一)多模融合,数据管理新突破
实现了多种数据管理模型(搜索、向量、NXD、RDF)的深度融合,构建了统一的多模数据库管理系统。通过增强的KSQL语言实现结构化、半结构化及非结构化数据的融合处理,并提供标量、全文与向量数据的混合查询。
(二)智能索引,检索效率大提升
集成多种向量索引算法(IVF、IVF-PQ、HNSW、FLAT),并实现智能索引(QVECTOR)和低内存磁盘索引(DiskVECTOR),其中智能索引可根据数据规模与维度自适应选择最优算法与参数,在召回率与响应速度之间实现有效平衡,支持高性能并行索引构建。
(三)语义检索,精准匹配新高度
运用“多路召回和融合排序”的智能语义检索方法,在统一语义向量空间中对文本进行联合表征与检索,提升了语义相关性保持与精确匹配能力,实现了更高精度的跨域检索效果。
(四)分布式架构,弹性扩展强支撑
采用分布式架构与读写分离设计,通过统一版本管理及增量同步协议保证一致性,并支持在线水平扩展至百级节点。并行计算与集群部署机制确保高可用性与高扩展性,有效支撑大规模数据的弹性管理与高性能检索。